Introduction
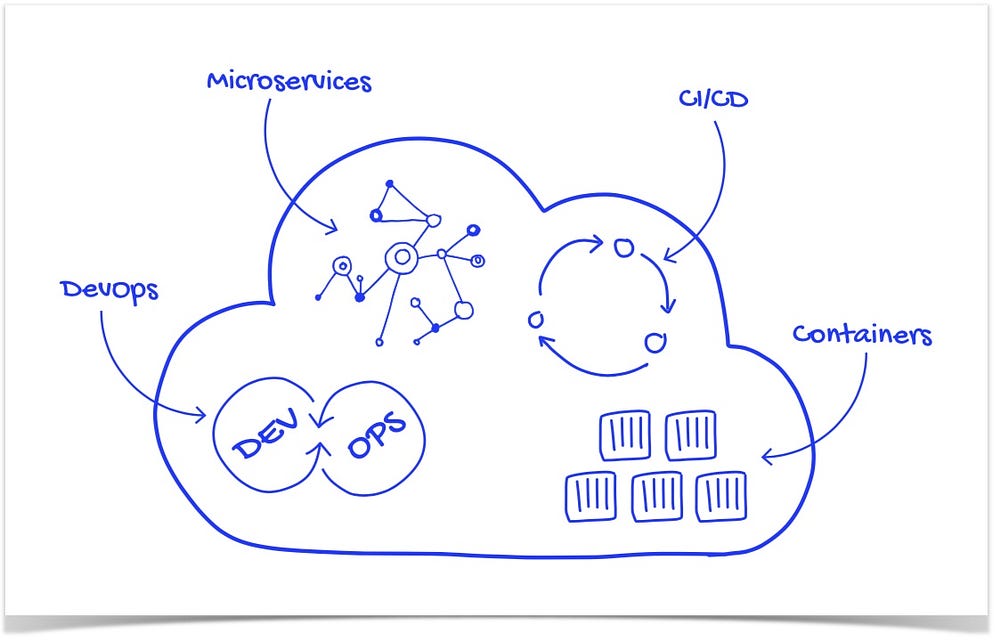
Cloud native is an approach for building applications as micro-services and running them on a containerised and dynamically orchestrated platforms that fully exploits the advantages of the cloud computing model. Cloud-native is about how applications are created and deployed, not where. Such technologies empower organisations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. These applications are built from the ground up, designed as loosely coupled systems, optimised for cloud scale and performance, use managed services and take advantage of continuous delivery to achieve reliability and faster time to market. The overall objective is to improve speed, scalability and, finally, margin.
Speed — Companies of all sizes now see a strategic advantage in being able to move quickly and get ideas to market fast. By this, we mean moving from months to get an idea into production to days or even hours. Part of achieving this is a cultural shift within a business, transitioning from big bang projects to more incremental improvements. At its heart, a Cloud Native strategy is about handling technical risk. In the past, our standard approach to avoiding danger was to move slowly and carefully. The Cloud Native approach is about moving quickly by taking small, reversible and low-risk steps.
Scalability — As businesses grow, it becomes strategically necessary to support more users, in more locations, with a broader range of devices, while maintaining responsiveness, managing costs and not falling over
Margin — In the new world of cloud infrastructure, the strategic goal is to be to pay for additional resources only as needed — as new customers come online. Spending moves from up-front CAPEX (buying new machines in anticipation of success) to OPEX (paying for additional servers on-demand).
Scalability — As businesses grow, it becomes strategically necessary to support more users, in more locations, with a broader range of devices, while maintaining responsiveness, managing costs and not falling over
Margin — In the new world of cloud infrastructure, the strategic goal is to be to pay for additional resources only as needed — as new customers come online. Spending moves from up-front CAPEX (buying new machines in anticipation of success) to OPEX (paying for additional servers on-demand).
Role Of CNCF
Cloud Native Computing Foundation is an open source software foundation housed in the Linux Foundation and includes big names such as Google, IBM, Intel, Box, Cisco, and VMware etc, dedicated to making cloud-native computing universal and sustainable. Cloud native computing uses an open source software stack to deploy applications as microservices, packaging each part into its own container, and dynamically orchestrating those containers to optimize resource utilisation. According to the FAQ on why CNCF is needed — Companies are realising that they need to be a software company, even if they are not in the software business. For example, Airbnb is revolutionising the hospitality industry and more traditional hotels are struggling to compete. Cloud native allows IT and software to move faster. Adopting cloud-native technologies and practices enables companies to create software in-house, allows business people to closely partner with IT people, keep up with competitors and deliver better services to their customers.
Cloud Native Design Principles
Designed As Loosely Coupled Microservices
Microservice is an approach to develop a single application as a suite of small services, each running in their own process and communicating using lightweight protocols like HTTP. These services are built around business capabilities and are independently deployable by fully automated deployment machinery.
Developed With Best-of-breed Languages And Frameworks
Each service of a cloud-native application is developed using the language and framework best suited for the functionality. Cloud-native applications are polyglot. Services use a variety of languages, runtimes and frameworks. For example, developers may build a real-time streaming service based on WebSockets, developed in Node.js, while choosing Python for building a machine learning based service and choosing spring-boot for exposing the REST APIs. The fine-grained approach to developing microservices lets them choose the best language and framework for a specific job.
Centred Around APIs For Interaction And Collaboration
Cloud-native services use lightweight APIs that are based on protocols such as representational state transfer (REST) to expose their functionality. Internal services communicate with each other using binary protocols like Thrift, Protobuff, GRPC etc for better performance
Stateless And Massively Scalable
A cloud-native app stores its state in a database or some other external entity so instances can come and go. Any instance can process a request. They are not tied to the underlying infrastructure which allows the app to run in a highly distributed manner and still maintain its state independent of the elastic nature of the underlying infrastructure. From a scalability perspective, the architecture is as simple as just by adding commodity server nodes to the cluster, it should be possible to scale the application
Resiliency At The Core Of the Architecture
According to Murphy’s law — “Anything that can fail will fail”. When we apply this to software systems, In a distributed system, failures will happen. Hardware can fail. The network can have transient failures. Rarely, an entire service or region may experience a disruption, but even those must be planned for. Resiliency is the ability of a system to recover from failures and continue to function. It’s not about avoiding failures, but responding to failures in a way that avoids downtime or data loss. The goal of resiliency is to return the application to a fully functioning state following a failure. Resiliency offers the following:
- High Availability — the ability of the application to continue running in a healthy state, without significant downtime
- Disaster Recovery — the ability of the application to recover from rare but major incidents: non-transient, wide-scale failures, such as service disruption that affects an entire region
One of the main ways to make an application resilient is through redundancy. HA and DR are implemented using multi node clusters, Multi region deployments, data replication, no single point of failure, continuous monitoring etc.
Following are some of the strategies for implementing resiliency:
- Retry transient failures — Transient failures can be caused by momentary loss of network connectivity, a dropped database connection, or a timeout when a service is busy. Often, a transient failure can be resolved simply by retrying the request
- Load balance across instances — Implement cluster everywhere. Stateless applications should be able to scale by adding more nodes to the cluster
- Degrade gracefully — If a service fails and there is no failover path, the application may be able to degrade gracefully while still providing an acceptable user experience
- Throttle high-volume tenants/users — Sometimes a small number of users create excessive load. That can have an impact on other users, reducing the overall availability of your application
- Use a circuit breaker — The circuit breaker pattern can prevent an application from repeatedly trying an operation that is likely to fail. The circuit breaker wraps calls to a service and tracks the number of recent failures. If the failure count exceeds a threshold, the circuit breaker starts returning an error code without calling the service
- Apply compensating transactions. A compensating transaction is a transaction that undoes the effects of another completed transaction. In a distributed system, it can be very difficult to achieve strong transactional consistency. Compensating transactions are a way to achieve consistency by using a series of smaller, individual transactions that can be undone at each step.
Testing for resiliency — Normally resiliency testing cannot be done the same way that you test application functionality (by running unit tests, integration tests and so on). Instead, you must test how the end-to-end workload performs under failure conditions which only occur intermittently. For example: inject failures by crashing processes, expired certificates, make dependent services unavailable etc. Frameworks like chaos monkey can be used for such chaos testing.
Packaged As Lightweight Containers And Orchestrated
Containers make it possible to isolate applications into small, lightweight execution environments that share the operating system kernel. Typically measured in megabytes, containers use far fewer resources than virtual machines and start up almost immediately. Docker has become the standard for container technology. The biggest advantage they offer is portability.
Cloud-native applications are deployed using Kubernetes which is an open source platform designed for automating deployment, scaling, and management of containerised applications. Originally developed at Google, Kubernetes has become the operating system for deploying cloud-native applications. It is also one of the first few projects to get graduated at CNCF.
Agile DevOps & Automation Using CI/CD
DevOps, the amalgamation of “development” and “operations describes the organisational structure, practices, and culture needed to enable rapid agile development and scalable, reliable operations. DevOps is about the culture, collaborative practices, and automation that aligns development and operations teams so they have a single mindset on improving customer experiences, responding faster to business needs, and ensuring that innovation is balanced with security and operational needs. Modern organisations believe in merging of development and operational people and responsibilities so that one DevOps team carries both responsibilities. In that way you just have one team who takes the responsibility of development, deployment and running the software in production.
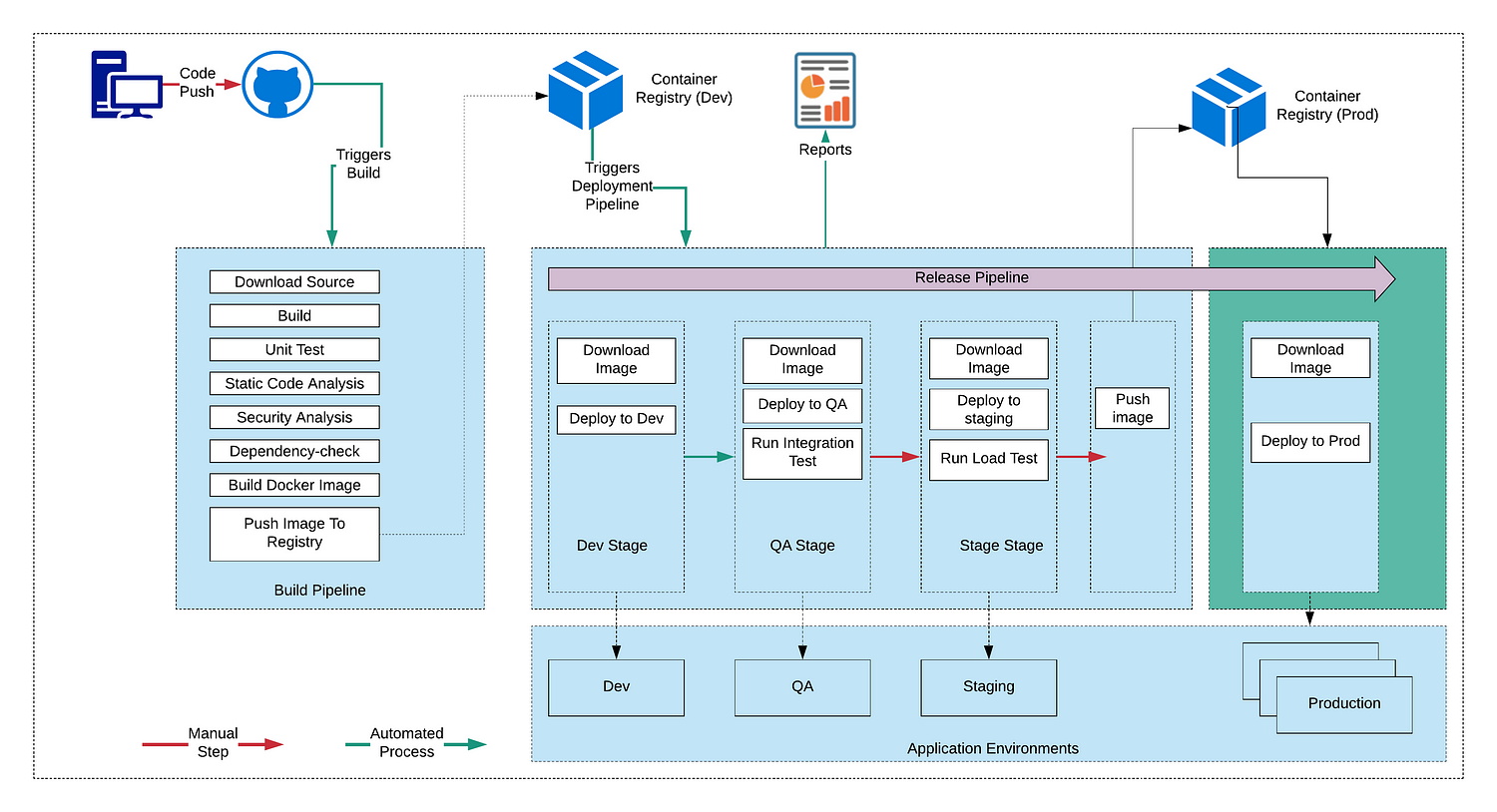
Continuous integration (CI) and continuous delivery (CD) is a set of operating principles that enable application development teams to deliver code changes more frequently and reliably. The technical goal of CI is to establish a consistent and automated way to build, package, and test applications. With consistency in the integration process in place, teams are more likely to commit code changes more frequently, which leads to better collaboration and software quality.
Continuous delivery picks up where continuous integration ends. CD automates the delivery of applications to selected infrastructure environments. It picks up the package built by CI, deploys into multiple environments like Dev, QA, Performance, Staging runs various tests like integration tests, performance tests etc and finally deploys into production. Continuous delivery normally has few manual steps in the pipeline whereas continuous deployment is a fully automated pipeline which automates the complete process from code checkin to production deployment.
Elastic — Dynamic scale-up/down
Cloud-native apps take advantage of the elasticity of the cloud by using increased resources during a use spike. If your cloud-based e-commerce app experiences a spike in use, you can have it set to use extra compute resources until the spike subsides and then turn off those resources. A cloud-native app can adjust to the increased resources and scale as needed.








No comments:
Post a Comment